


I recently had the opportunity to talk about data and AI/ML products with some hardware and software executives who are busy figuring out how the AI explosion is impacting their business. While most data scientist, AI engineers, MLOps engineers and managers can tell you a list of specific techniques, skills, concepts, algorithms, etc. that are important to understand to do their respective jobs well, I have not seen a concise explanation of what differentiates a AI/ML product from a software or hardware product, besides that it uses AI/ML. Captain Obvious (e.g. me ) may have just missed the memo, but I haven’t found it yet :)
I actually think that maybe people are slightly misdirected by the question itself. The distinguishing factor is the volume of data, not AI/ML. Specifically, it is the quantity and quality of data that you can bring to bear on a problem, plus your ability to convert that data into “value.” Currently, AI algorithms are dominating our ability to do this, but previously we had (have) Google and before that Inktomi, to name a few well known examples.
Data v1.0 - v3.0
Inktomi, a company younger people may not have heard of, pioneered the use of large clusters of commodity hardware for the “embarrassingly parallel” problem of web crawling and search. This allowed them to dramatically scale the size of web indexes, which in turn allowed their customers to scale cheaper and therefore bigger than companies that used “big-iron” systems with lots of unneeded complexity. This was a very clear case where the scale of data-under-management led directly to better quality and therefore business value.
Google illustrates how improving quality at scale also leads to value. PageRank outperformed Inktomi-based search engines not by scaling bigger (their index started out much smaller), but because the algorithm produced a step-change in quality relative to the status quo, at scale. It was not enough to have a way better algorithm: PageRank was (is) a better algorithm that scaled to the size of a massive web index.
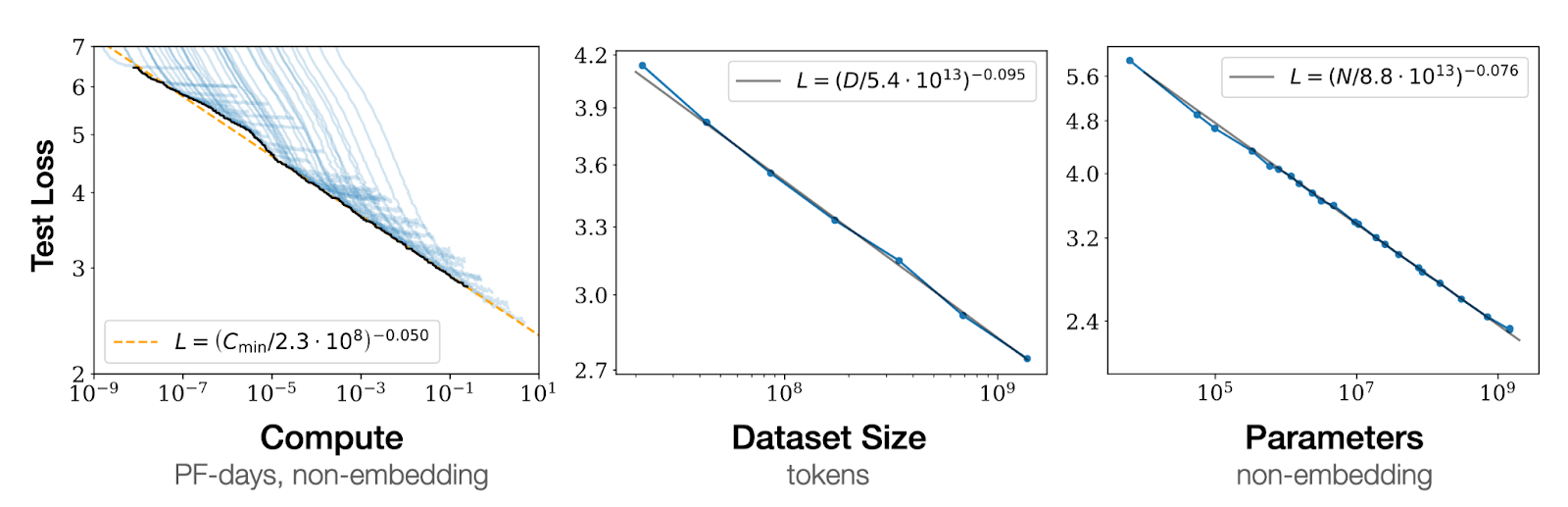
OpenAI and the Transformer architecture are the recent, well-known parallel to this. Lots of work contributed to the “Scaling Hypothesis,” but the canonical paper is probably Scaling Laws for Neural Language Models from OpenAI (see the image above).
This paper argued that scaling model size is the most compute-efficient way to train a model. The authors illustrated several power laws for scaling language models, and almost certainly used it internally to justify scaling GPT-3 to 175B parameters. This paper sparked a cottage industry of scaling law papers, including Training Compute-Optimal Large Language Models, or “the Chinchilla paper,” which argues that it is more efficient to scale training data with model size, leading to a common rule of thumb of 20 tokens per parameter (e.g. “Chinchilla Optimal”).
Later research argues that inference performance is more important, since you pay the cost of training once but inference over a longer period of time, in which case, training even longer is more cost effective. Many models are now trained with 1000 tokens or more per parameter, and often reach 10s of trillions of tokens.
Stepping back, these papers all argue that
scaling works (e.g. more resources leads to higher quality, like Inktomi) and/or
there are better ways to scale (like Google)
Notice that all the papers discuss the efficiency of scaling: “how much value do I get for the work I put in?” This is not a coincidence, and this is different from software and hardware products. Here’s a table I put together:
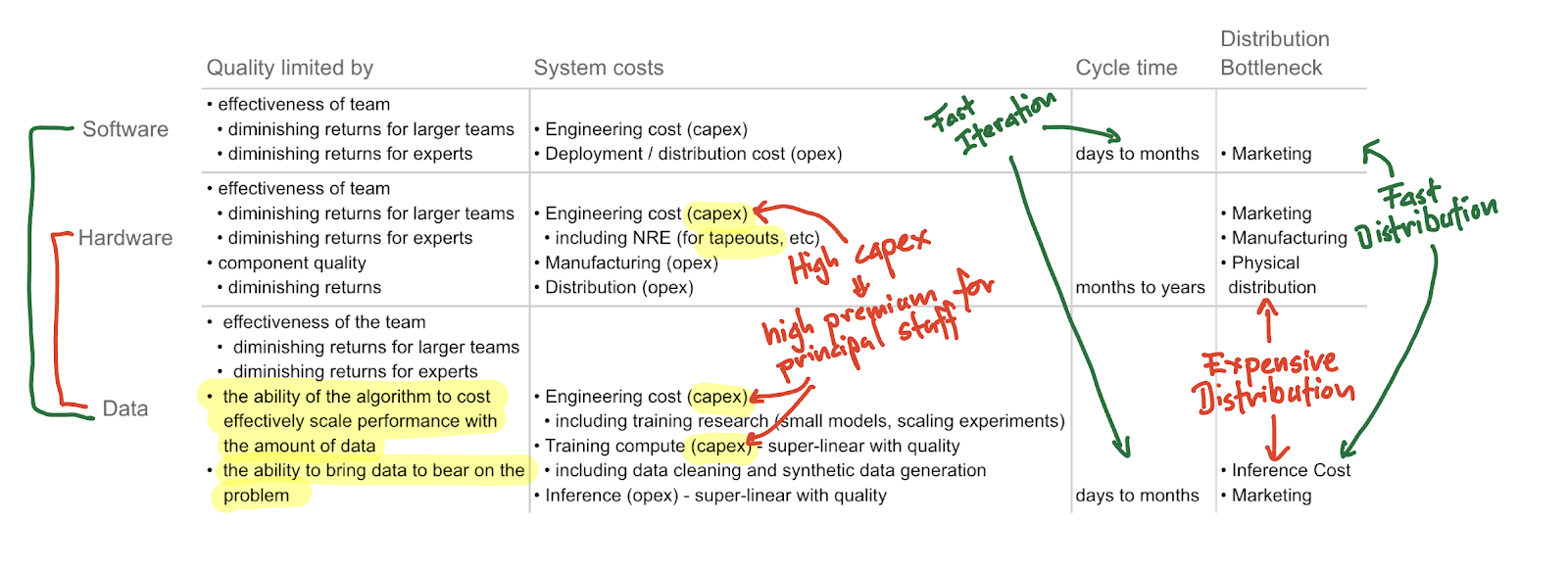
On the one hand, data project costs scale similarly to hardware projects. Replace “training” with “tapeout”, and “physical distribution” with “inference cost”, and the two look quite similar. On the other hand, data projects iterate and distribute more like software projects. Hardware turns can take months to years vs. days to months for software and data products.
The consequence of this is that the value of early, fast iteration on quantifying potential value and reducing risk are table stakes. If you cannot build a team and infrastructure to do this, you cannot compete.
Consider the following analogies: assigning a team of bright software engineers to build an ASIC might eventually result in a working chip, but it’s likely to either take a really long time to get to tapeout (slow and expensive), or you’re likely to do a lot of spins (slow and really expensive). Similarly, assigning a software team to build a SAS product without a modern CI/CD system is likely to result in persistently slow delivery and low quality, and therefore poor traction.
A Modest Proposal?
Analogously, data teams have a unique set of skills and tools that make it possible to iterate quickly, derisk data products, quantify cost and value, and set appropriate scale targets. I recently reviewed a proposal by a software engineer to use LLMs to summarize test results from test logs. He had done a quick proof-of-concept using a small log file that is annoying for his team to parse visually. His PoC dumped the log file in, and prompted for abnormal results, and the team finds it useful. Great! Low investment, relatively high return!
The proposal, however, was to scale this approach to many more, much larger log files, add interactive “chat-with-your-logs,” dynamic queries to a database written by an LLM, and use fine-tuning on OpenAI’s endpoints to improve “performance.” This PoC and proposal lacked a lot of the fundamentals: besides a clear use case and clear customer (generic product basics), it lacked an understanding of the scope of the effort and data required, metrics and evals, an estimate of training and inference cost, a quantification of the user’s problem, an understanding of the standard approaches to similar problems (hint: not an LLM), and an understanding of the limitation of the proposed models, to name a few important ones.
To be clear, I would never argue that using an off the shelf AI/ML product on a well understood, low risk project requires a huge upfront analysis. In fact, I think the opposite: I’m a big fan of easy wins using off the shelf tools (AI or not), small amounts of data and low cost. Who is not? My point is that it takes experience to recognize the difference:
What can an off-the-shelf model or tool accomplish?
How much data do I need for this problem?
How big do I need to scale to break even?
This last one is really the crux of the issue: whereas software and hardware engineers are typically not as involved with the product and business question of scale, scale is central to the data team’s activity. In the paper above, OpenAI encapsulates years of up-front learning about scaling LLMs into a set of equations that show that more data and compute going in means more quality coming out for LLMs at the scales they could extrapolate to. Whereas scaling investment in a hardware or software product will have diminishing returns, LLMs (e.g. a data product) at the scales they investigated did not (on the log scale). This is different!
Building a data moat
A further consequence of this is that as you scale your data set, you can hopefully scale your customer base because of increased quality (if you have designed your product well). This means you can afford to train with more data. It also means you have reduced the risk of training larger, higher quality models. This apparently leads to a data/quality flywheel:

I say “apparently” because Google Search and OpenAI’s ChatGPT are clear examples of this.
Another compelling similarity between hardware and data products is that for products that require specialized teams and/or a lot of up-front investment of capital and time, there is a significant barrier to entry and therefore first-mover advantage. Google, who invented the Transformer architecture and has a massive talent pool and hardware resources, has had trouble even competing with OpenAI until recently because it failed to scale first.
The data/quality flywheel mentioned above compounds this effect: as the business grows its customer base, it has more revenue and data available to improve its quality. This makes it even harder to catch, as we’ve seen with OpenAI’s continued dominance, even with heavyweights Anthropic and Google chasing. IF you can build a data / quality flywheel with your business, you likely have a very good product on your hands.
Little bets, big bets
At the risk of repeating myself, the data team brings the capability to quickly iterate on ideas to find the high expected value (EV) ones: quick and easy wins on the one hand and high risk / high reward ones on the other. A team with the right tools and skills will be able to quickly bring data to bear on ideas; run small experiments; and then declare victory, reject/pivot or ratchet up scale as the team refines the idea into a product. This is the key capability: to vet and set appropriate scale targets.
On the other hand, a team without adequate executive support, patience and resources will find itself unable to quickly sift through ideas and iterate as it ramps to scale to an appropriate level. Instead it will most likely get bogged down in infrastructure problems and unnecessary complexity.
To be clear, “appropriate level” will usually mean medium to small. Power laws dictate that we won’t have too many really big data applications, and the bigger the fewer.
The Rise of the AI Engineer
Getting back to the original point of this post, the key question is “how much data do I need to use to be successful?” If you want to bring an off-the-shelf AI/ML product to bear on a relatively small data set, a good software engineer can probably do a quick PoC to judge whether the approach will work, as long as they understand that their results will almost certainly not extrapolate well. On the other hand, if the project involves really big data sets and potentially sophisticated learning techniques, you probably need to invest in a dedicated team that understands how to plan, measure, iterate and potentially scale.
A year and a half ago, however, Swyx posted The Rise of the AI Engineer, in which he argued that
… software engineering will spawn a new subdiscipline, specializing in applications of AI and wielding the emerging stack effectively, just as “site reliability engineer”, “devops engineer”, “data engineer” and “analytics engineer” emerged.
The emerging (and least cringe) version of this role seems to be: AI Engineer.
I think this prediction has absolutely played out, with more and more focus on effectively designing and deploying applications of AI. The following diagram from that post has appeared all over the place
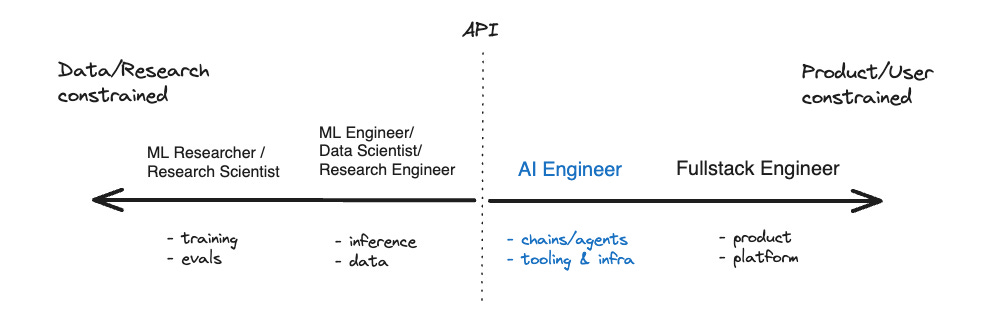
Three things have become more clear since that post:
AI will replace simple and even relatively complex coding tasks, and this probably means a dramatic shift in what software engineers do. Not that this wasn’t already pretty clear at the time, but as coding assistants have become standard equipment, the skill set needed by a software engineer has changed.
I have heard several times now the idea that more senior software engineers benefit disproportionately from AI coding assistants because they understand better how to put together smaller components into well tested, documented and deployed software systems.
A big part of AI Engineering actually is more like ML Engineering: understanding evals and scale issues
An executive recently asked me “Isn’t AI/ML just a tool, rather than a team?” My response is that it depends on which side of the API you sit (referencing the diagram above).
As AI coding assistants become more and more capable, your need for specialized software and even hardware engineers will probably reduce, and focus will necessarily shift to putting together systems that provide valuable user experiences with off-the-shelf AIs. This shift will disproportionately impact more junior engineers, so viewing AI/ML as a tool, and AI Engineers as a role with a unique skill set will absolutely give your young stars an opportunity to carve a niche and grow.
If, on the other hand, you have a lot of data and want to build a data / quality pipeline, you are going to need to a ML/AI team that understands data and scale.
AI Engineering
I haven’t written much about what an AI Engineer actually does because there is a lot of great information about that already. What We’ve Learned From A Year of Building with LLMs is one my favorite resources, and Eugene Yan is an excellent writer on ML and AI Engineering, plus lots of other topics.
Credits
A big thanks to @swyx for providing feedback and suggestions before I posted this!
I’d love to hear your thoughts and criticism. Comment here, or find me at
LinkedIn: @rj-honicky
BlueSky: @honicky.bsky.social
X: @honicky