
One thing I learned: weight streaming probably works well on GPUs
I wonder why it isn't a thing...


Sarah Chieng from Cerebras joined paper club last week to present Training Giant Neural Networks Using Weight Streaming on Cerebras Wafer-Scale Clusters. If you’re not familiar with Cerebras, they make dinner-plates wafer-scale chips designed for AI and other High Performance Computing applications that look like this:

By packing a huge number of processors plus memory on a single chip, they are able to avoid memory latency, although for IO-bound applications like training very large Neural Networks, it’s not clear to me that this matters very much.
It also allow them to do much more fine-grained parallel algorithms, although the exact mechanism is unclear to me. In any event, this enables unstructured sparse matrix multiplication, which they discuss at length in the paper.
While discussing the paper, a few of us wondered out loud whether we could apply the architecture that Cerebras uses in the paper to a GPU cluster. I decided to dig in on this a bit…
Weight Streaming
There are a lot of common ways to distribute Neural Network training:
Data Parallel (DP) - copy the full model to different devices and then sum the gradients from all of the devices before updating the weights for the next pass
Fully Sharded Data Parallel (FSDP) - shard the tensors of the model and optimizer over all of the devices, and reconstruct them when needed
Pipeline Model Parallel (PMP) - distribute layers over different devices and pipeline the activations through the different devices. Note that the backward pass creates tricky “bubbles” in the pipeline
Tensor Model Parallel (TMP) - spit the tensors in a clever way to minimize the need to syncronize between devices during updates
You can learn more about these techniques in the paper as well as in Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM, a great paper from NVIDIA that goes into a ton of detail about how these techniques scale.
Extreme pipelining
The idea of weight streaming is to keep the activations in memory and stream in the weights as they are needed for each stage of the model, for both forward and backwards passes. This is very similar to Pipeline Model Parallelism except that:
the weights move instead of the activations
the whole pipeline runs on the same device, step by step, and can start computation before a tensor is even fully loaded.
This is pretty cool, because as long as the batch size is big enough to keep the processor busy, you can pipeline the data transfer and keep the compute busy.
But what about the activations?
Note that the you need to keep all of the activations around in memory until they have been used in the backwards pass since back-propagation needs the weights and activations, plus the gradients from the previous layer.
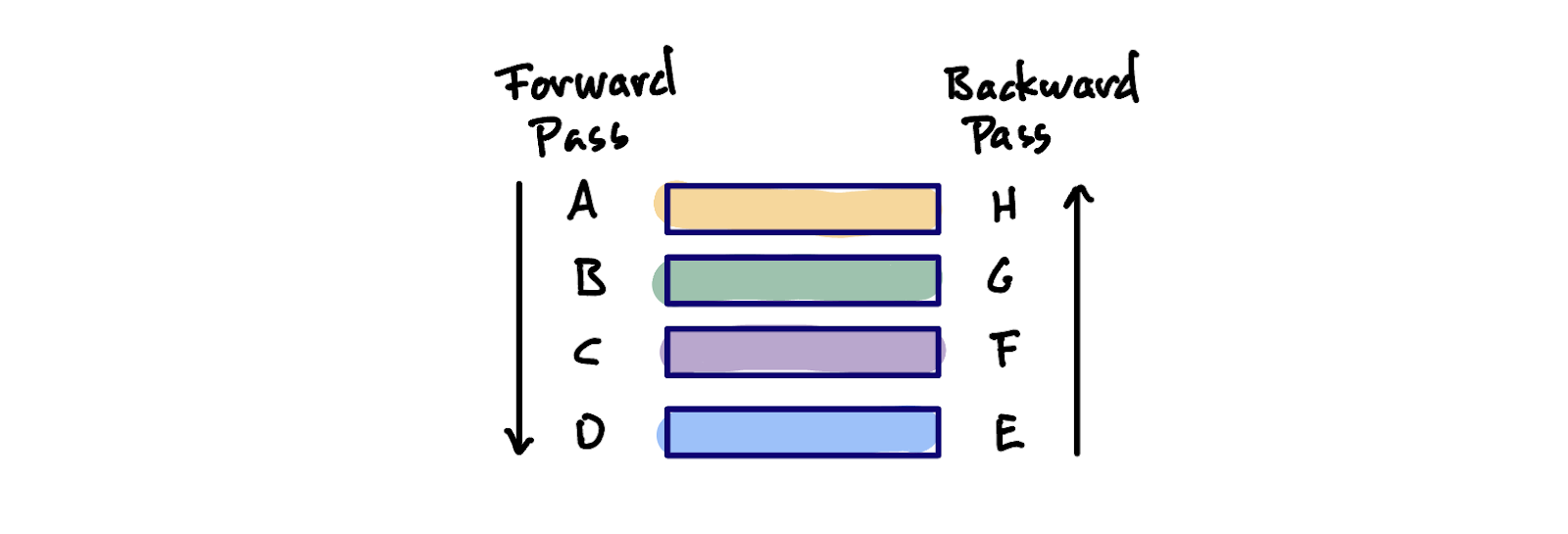
In this example, we need the activations from forward step A for backward step H, so at step E we need to have all of the activations in memory, or stream them in and out along with the weights.
As the model gets bigger, this puts down-pressure on the size of the batch, since more and more of the memory/bandwidth needs to be devoted to maintaining the activations of the model as the batch size goes up. On the other hand, pipelining the weight streaming with computation puts upwards pressure on the batch size. I suspect this is why they did not do actual experiments with larger models.

The largest model they trained was 25B, which is hardly persuasive in a scaling paper. Compare this with the Megatron paper, in which the authors trained models from 1.7B all the way to 1T (!).

This seems to be because scaling beyond this 25B would require that the Cerebras folks use the other types of model parallelism (tensor and/or pipeline), and/or stream the activations in and out with the weights and gradients.
Combining weight streaming with model parallelism increases bandwidth requirements since data movement is required for activations, between compute units, in addition to weights and gradients between the memory service and compute units. For this reason and reduced implementation complexity, we have focused on data parallelism ( Nm = Np = 1 and N = Nd ) in the Cerebras weight streaming implementation.
Timing pressure
Streaming activations in and out of the device would mean that the batch would need to be transferred out after a layer’s forward pass and back in before it is needed in the backwards pass. The tightest constraint would be in the second-to-last layer (since the last layer can just leave the activation in place).
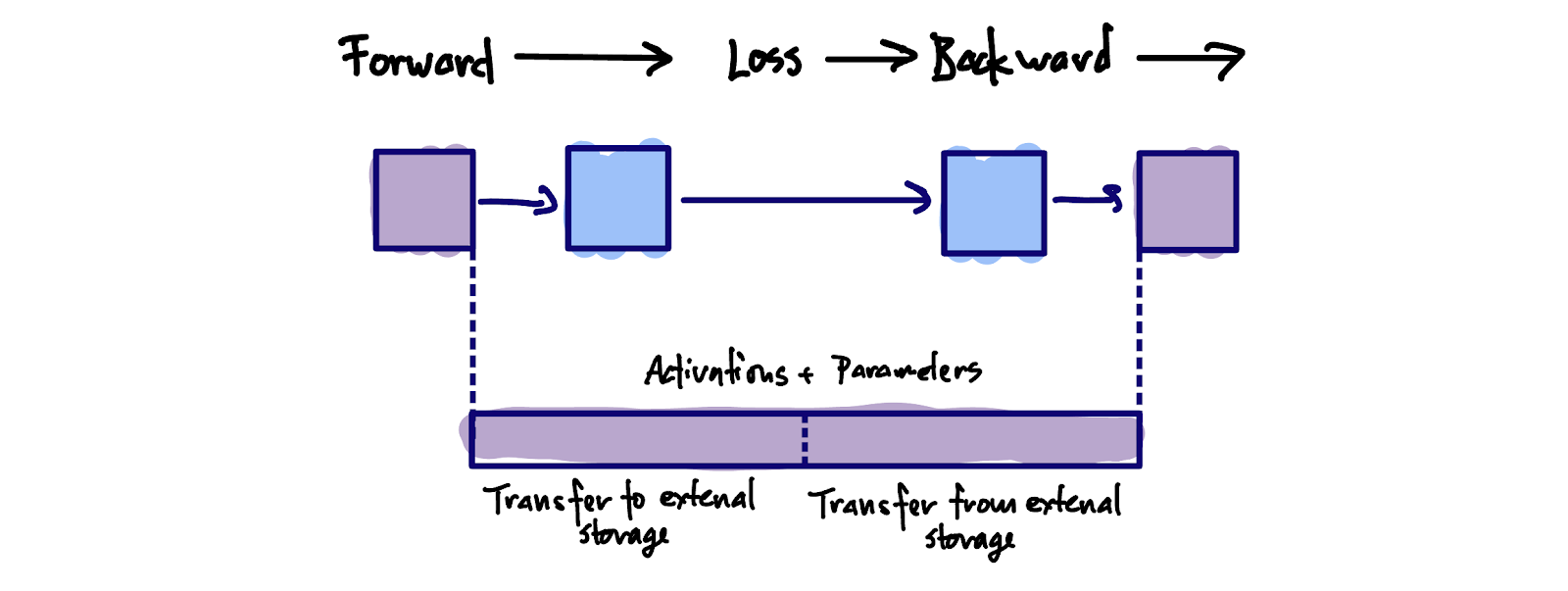
So, we would need
The batch size to be big enough to pipeline streaming the weights in and out with computation
The batch size to be small enough to stream in and out in the activations in the time it takes to do one forward step, the loss calculation and one backward step.
So streaming the activations in and out using FabricX (their hierarchical, compute/networking memory fabric) and MemoryX (their memory offload system) seems like it would be pretty tricky to get right.
Tensor Model Parallelism?
What about TMP instead? As the authors mentioned in the quote above, the standard approach to scaling to very large training runs is a combination of DP, PMP and TMP. Here’s a plot from the paper:

As models need more scaling than Data Parallelism can provide, it looks like people typically use TMP. In any event, Weight Streaming is very similar to PMP (see above), so TMP seems like a better technique to combine with Weight Streaming.
TMP would allow us divide the activations and weights between multiple devices. TMP minimizes communication overhead between devices by dividing the tensors up cleverly, and avoids stalls by pipelining the transfers that it does need to do with computations, so TMP seems like a good complement to Weight Streaming.
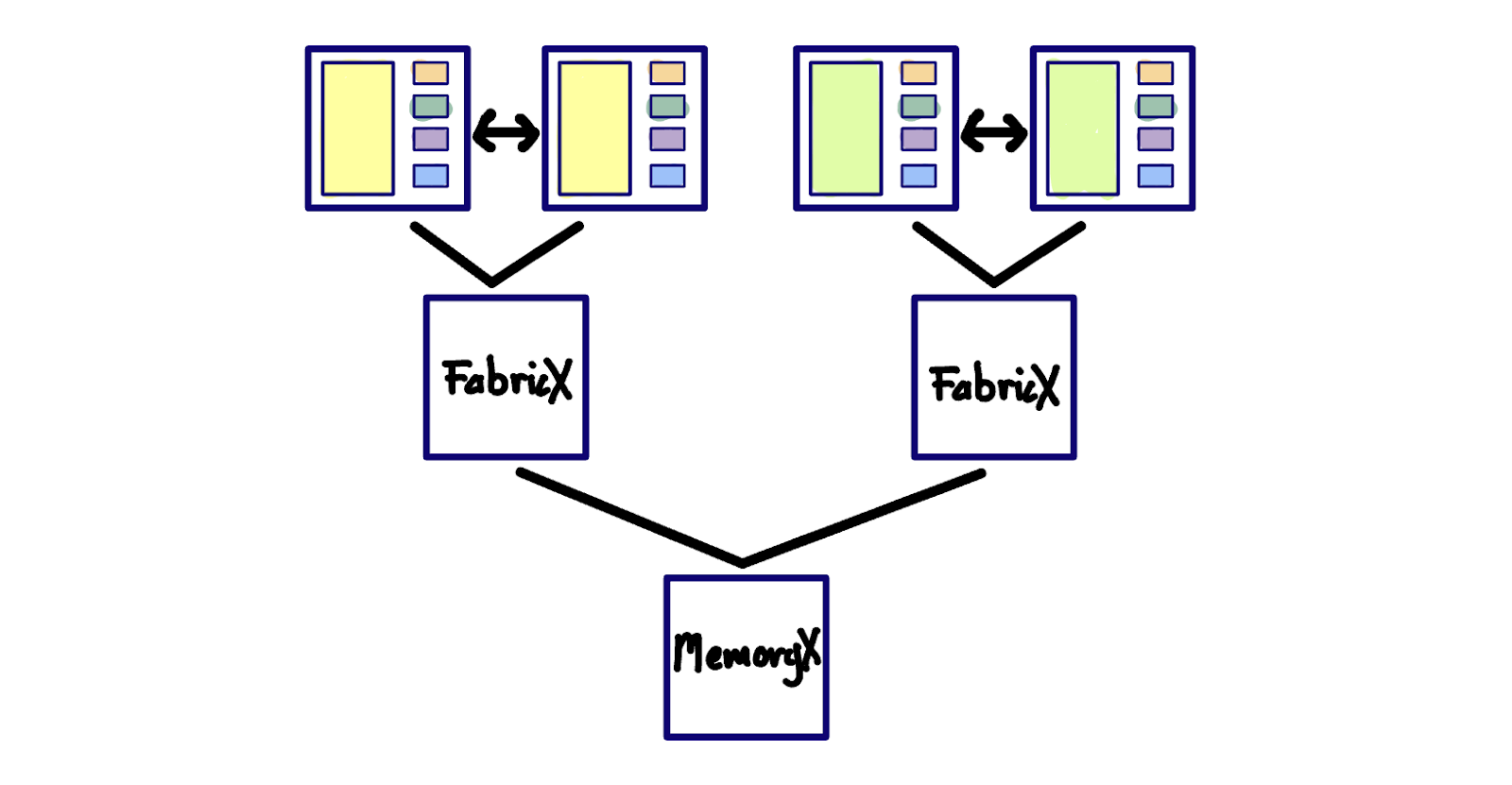
Weight Streaming + TMP seems like it may hit the sweet spot of avoiding transferring activations (except for the minimized communication to sync the sharded matrix multiplies in TMP), and thus reducing the pressure on the IO bottleneck helping to push up the utilization of the processor. The alleviating the IO bottleneck is what will ultimately drive processor utilization up, so eliminating unnecessary transfers, and pipelining will help the most in this regard.
It’s unfortunate that the authors didn’t explore this, since presumably Cerebras would like to sell their devices to companies like OpenAI and Tesla that are building mega-clusters for training massive models.
Could you do it with GPUs?
Getting back to the origin question, could you do weight streaming with a GPU cluster? And should you?
It turns out the TensorRT already has support for weight streaming from the CPU to GPU, and it integrates with PyTorch, so the hard part of the infrastructure is already there. The part that is left is the hierarchical memory management that pipelines the scatter/gather (see the diagram above). It seems like getting the pipelining right might be tricky but doable. I mean, look at this PMP schedule from the Megatron paper:
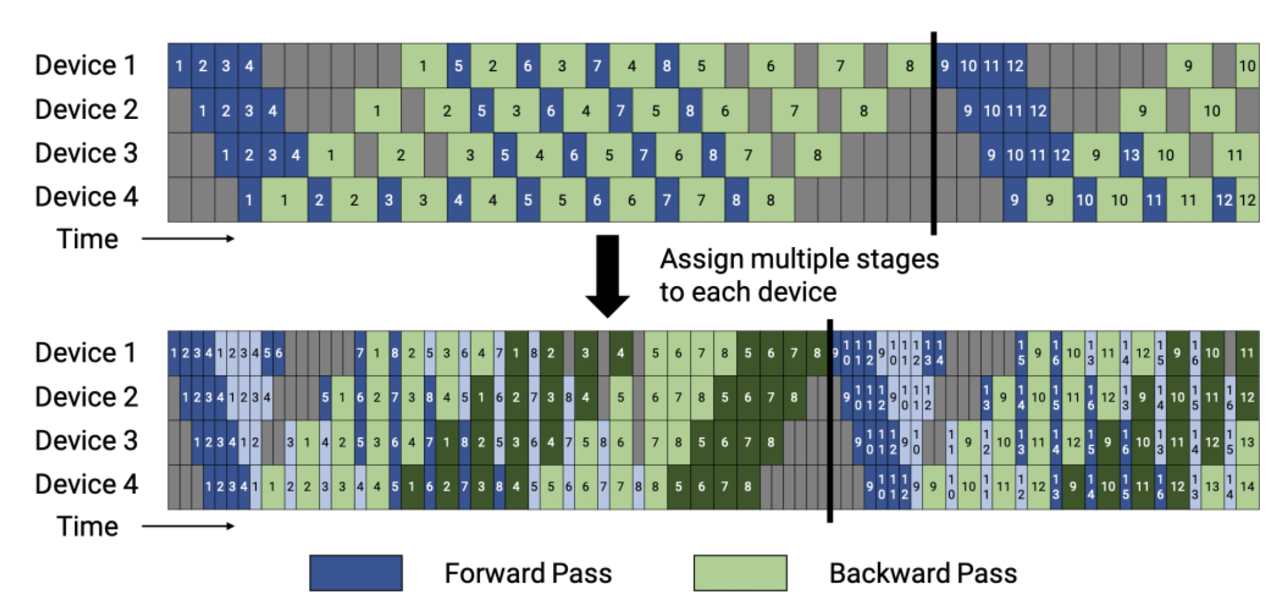
That looks tough, and they managed to do it, so I’m going to assume that you could write a pretty efficient scheduler similar to FabricX and MemoryX.
“Memory” Bandwidth?
A question remains: does a GPU have enough memory bandwidth to keep the processors busy long enough to hide the transfer latency?
H100 | WSE-2 | |
TFLOP/s | 989 | 75000 |
TB/s | 0.9 | 0.15 |
Ratio (TFLOP/s:TB/s) | 1099:1 | 500000:1 |
The H100 has a dramatically lower FLOPs to interconnect speed ratio, so it seems like anything the WSE-2 can pipeline, the H100 can easily pipeline too. So, yes, I think we can probably pull off doing Weight Streaming with memory offload for large models using the Cerebras memory offload architecture.
A cool take, a hot take
I think the Weight Streaming architecture that the paper describes might work to improve utilization on GPUs by eliminating pipeline stalls and offloading some of the easier weight arithmetic. It would be a fun experiment for someone with a bunch of H100s with really fast interconnects lying around, or even an older GPU cluster.
On the other hand, the ratio of compute to interconnect bandwidth seems like it will severely bottleneck the WSE-2 on data transfer, and all those awesome cores will be mostly idling during training. To be fair, the Cerebras folks recommend training for sparsity, and this will help to alleviate the interconnect bottleneck, but training to 90% sparse (which is above where they were able to train), and assuming that you can reduce data traffic by that percentage, you still end up with an effective ratio of 50000:1, so you’re probably still bottlenecked on memory transfer. My hot take: Cerebras optimized the wrong thing for AI workloads, although for many compute-bound scientific workloads it may help dramatically.
I’ll probably regret that…
I’d love to hear your thoughts. I’m on X @honicky and BlueSky @honicky.bsky.social and LinkedIn @rj-honicky.