
One thing I learned: embeddings are task-specific
We should probably include a prompt or fine tune to a specific type of task


Well, I haven’t posted in the past few months, although I’ve been busy with learning, including presenting (video, slides) the fascinating paper Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models for the Latent Space Paper Club. Sadly, my exhaust output has been lacking.
At the same time, the posts I have done are pretty in-depth and some of them are time-consuming to read (let alone write). So I’ve decided to start noting “something I learned” while reading a paper, researching a topic, etc. Since I read one paper a week for the Latent Space Paper Club at a minimum, that means I should (in theory) be able to post once per week!
I still plan to follow up on my last post about post-quantization loss recover using LoRAs, and I am working on some ideas about log-file modeling, but I also want to write some more regular, bite-sized stuff.
So…
While reading about embeddings…
At Paper Club this week, swyx went over a few papers/blogs about text embeddings. We covered
The Nomic Embed and jina-embeddings-v3 papers both go into a lot of detail about the training sets they use. I hadn’t realized that the newer models use a multi-stage training process:
Pretraining - maybe pretrain a BERT-like model or just use a BERT variant like RoBERTa
Unsupervised Contrastive Pretraining - Train on large data sets that have natural pairs and/or rankings such as
| Description | Size (#Lines) | | --- | --- | | (Question, Answer)-Pairs from Google auto suggest | 3,012,496 | | (Title, Answer) pairs from Yahoo Answers | 1,198,260 | | (Question, Answer, Negative)-Triplets from MS MARCO Passages dataset | 499,184 | | (Title, Title) pairs of duplicate questions from StackExchange | 304,525 | | (Question, Answer)-Pairs from ELI5 dataset | 325,475 |
Supervised Contrastive Fine-tuning - Fine tune the model on smaller, higher quality pairs of data, mostly human annotated
Task-specific prefixes
The interesting thing to me was that especially in step 3, the datasets were from a variety of different NLP tasks:
Retrieval - Query-document retrieval task
Clustering documents - visualizing and understanding a corpus as a whole
Classification - text classification, such as sentiment analysis
Text similarity - Semantic text similarity, general symmetric retrieval, recommendation, finding similar items, deduplication
This causes a problem: different tasks might consider different documents as better matches. From Nomic Embed:
Consider the case of determining which response is closest to the question ”What is the capital of France?”:
- “What is the name of the capital city of France?
- “Paris is the capital of France.”
A semantic similarity task would consider the first closest, while a question answering task would consider the second closest.
They resolve this by add a prefix to the query-document pair:
Prefixes enable the model to distinguish between the behaviors specified by each of these tasks. We use the following task-specific prefixes:
• search.query
• search.document
• classification
• clustering
inspired by Reimers et al. (2023).
For example, using the example above, they might use something like
search.query What is the capital of France? paired with search.document Paris is the capital of France.
vs.
clustering What is the capital of France? paired with clustering What is the name of the capital city of France?
Wow! I didn’t realize that they were adding task-specific prefixes to the training data. This seems to imply that that we should also add a prefix during inference time. Unfortunately, they didn’t study this in the paper (it would be a fun follow-up though).
Task-specific adapters
jina-embeddings-v3 leans into this concept by actually training task-specific LoRAs to use along with the base model.
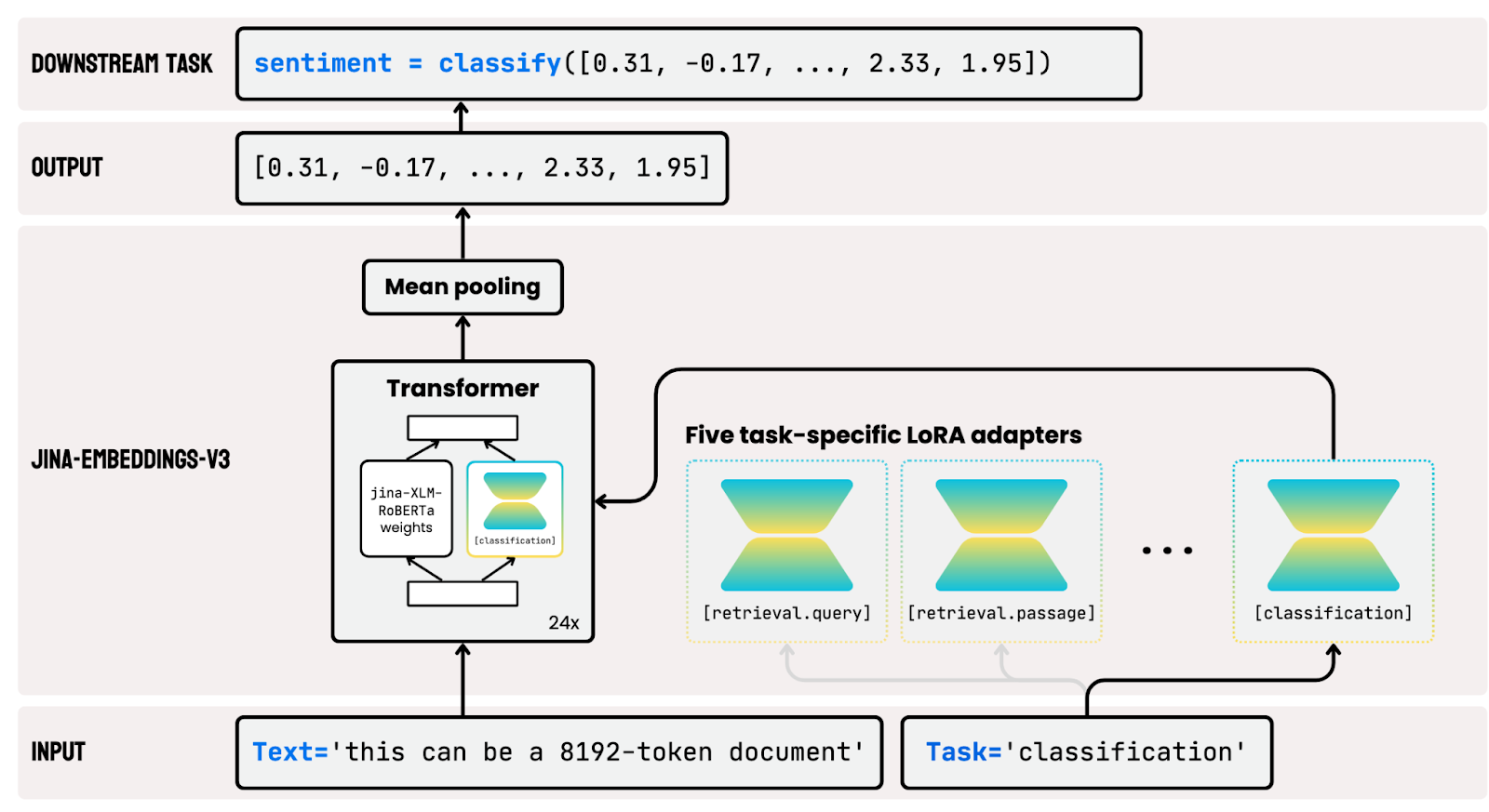
Strangly, their ablation study didn’t address exactly how much these adapters actually help.
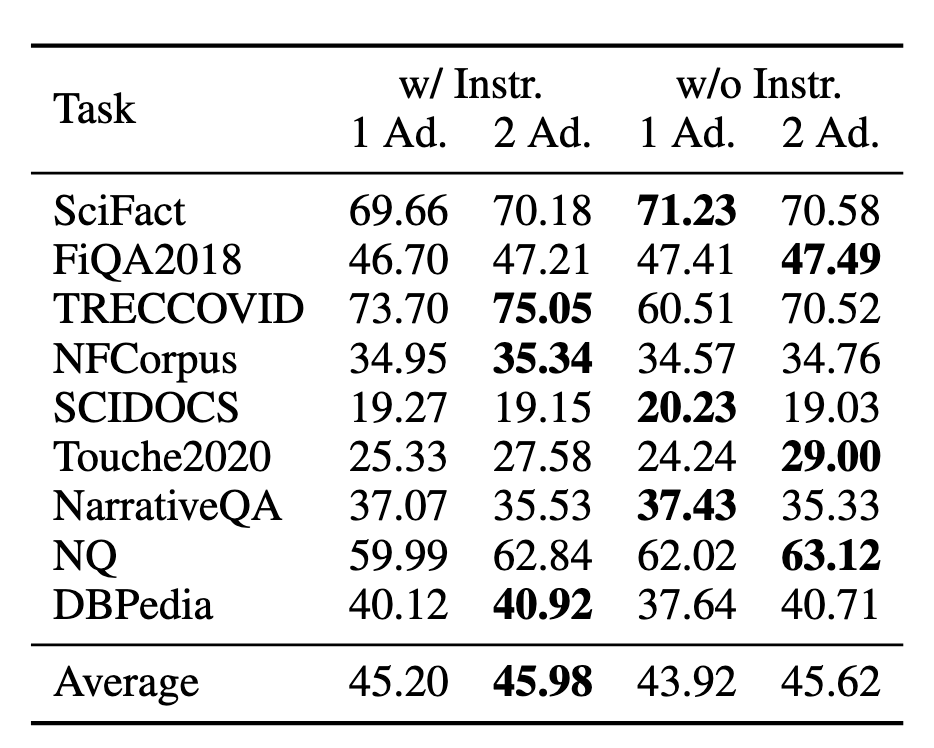
“w/ Instr” means “with instructions"; they added a prompt basically.
“1 Ad.”/”2 Ad.” means 1/2 adapters - they added one or two loras to the model
In this table, adding a prompt has about as much impact as adding a second LoRA, you don’t get much benefit from adding a second LoRA if you add a prompt.
I find it strange that they didn’t show their performance with NO LoRAs in this table. I suppose that they assume you will always use one LoRA, but I would like to understand the performance difference.
They did show performance difference for a small part of the dataset that they added in order to resolve problems with Jina-v2:

With the caveat that the dataset they are studying in this table is a small dataset designed to study the difference in performance on a few hard examples, we can compare the performance between jina-embeddings-v3* and jina-embeddings-v3** to understand the impact of the classification adapter. For their model, in these cases, it seems to make a big difference.
Takeaways
If the embedding model you are using was trained using task-specific prefixes, I suspect that adding the appropriate prefix to the query will help, although that’s far from clear since the authors didn’t study it
It seems like a prompt about the task the embedding is being used for might also help improve the embedding
It’s clearly a good idea to read the paper(s) about the specific embedding model(s) you are considering to understand how to use it in detail
As always, feedback, corrections and criticism are highly appreciated. Happy Thanksgiving!